
Antes de mais nada, gostaria de dizer que esse não é um post para iniciantes em programação, muito menos para iniciantes em Python. Vou abordar alguns assuntos e dar algumas explicações, considerando que você já possui certos conhecimentos prévios – que não vou explicar aqui. Fique a vontade para utilizar os comentários, ou entrar em contato direto comigo para tirar dúvidas ou pedir informações sobre como adquirir esses outros conhecimentos, se for o caso.
Concorrência e paralelismo
Pode parecer a mesma coisa, mas não é. Vamos as definições:
Paralelismo
Acontece quando duas ou mais tarefas são executadas, literalmente, ao mesmo tempo. Necessita, obviamente, de um processador com múltiplas cores, ou múltiplos processadores para que mais de um processo ou thread seja executado ao mesmo tempo.
Concorrência
Quando duas ou mais tarefas podem começar a ser executadas e terminar em espaços de tempo que se sobrepõem, não significando que elas precisam estar em execução necessariamente no mesmo instante. Ou seja, você tem concorrência quando:
- mais de uma tarefa progride ao mesmo tempo em um ambiente com múltiplos CPUs/núcleos;
- ou no caso de um ambiente single core, duas ou mais tarefas podem não progredir no mesmo exato momento, mas mais de uma tarefa é processada em um mesmo intervalo de tempo, não esperando que uma tarefa termine por completo antes de dar início a outra.
É a possibilidade do processador executar instruções ao mesmo tempo que outras operações, como, por exemplo I/O, permitindo que tarefas sejam executadas concorrentemente pelo sistema. A concorrência é o princípio básico para permitir o projeto e implementação de sistemas multitarefas.
Sistemas multitarefas são sistemas em que mais de um programa pode estar em execução ao mesmo tempo. Ou seja, é o contrário do monotarefa, onde somente um programa pode estar em execução por vez, deixando o processador dedicado exclusivamente a essa tarefa.
Em sistemas monotarefa, o processador é subutilizado e fica ocioso na maior parte do tempo esperando por outros componentes, como I/O.
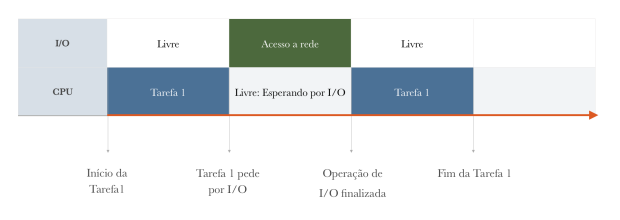
Fig. 1: Situação típica de uma aplicação monotask
Já em sistemas multitarefas, podemos utilizar o tempo de processamento ocioso para trocar de contexto e executar outras tarefa.

Fig. 2: Exemplo de situação multitask.
Na figura 2, podemos observar que quando a tarefa 1 pede por algum recurso externo, que tornaria o processador ocioso, utilizamos o tempo de processador para realizar outra tarefa, chamada de tarefa 2. Quando o recurso requisitado por tarefa 1 estiver pronto, podemos retomar a execução, pausando tarefa 2, etc… Dessa forma, podemos escalonar o uso de CPU.
Essa utilização concorrente da CPU deve ser implementada, de forma que as pausas e retomadas no uso de CPU mantenha idêntico o estado de uma determinada tarefa.
Classificação de Processos
Processos podem ser classificados como CPU Bound ou I/O Bound, de acordo com a utilização de CPU ou I/O. Saber distinguir entre as duas situações é muito importante para conseguirmos arquitetar adequadamente uma solução.
CPU Bound
Um tipo de computação em uma aplicação, cujo maior fator determinante para o tempo no qual ela vai levar para terminar, é determinado pela velocidade da CPU, pois passam a maior parte do tempo em estado de execução, utilizando o processador. Ou seja: CPUs mais rápidos fazem com que a computação seja mais rápida, terminando em um tempo menor. São exemplos de atividades/aplicações com soluções CPU Bound:
- Computações matemáticas intensas
- Algoritmos de busca e ordenação em memória
- Processamento e reconhecimento de imagem
I/O Bound
 Ao contrário de computações CPU Bound, passa a maior parte em estado de espera por realizar muitas operações de I/O. Esse tipo de computação é, obviamente, determinado pelo tempo gasto esperando por operações de input/output. São exemplos de atividades/aplicações I/O Bound, e suas velocidades de execução são afetadas por :
Ao contrário de computações CPU Bound, passa a maior parte em estado de espera por realizar muitas operações de I/O. Esse tipo de computação é, obviamente, determinado pelo tempo gasto esperando por operações de input/output. São exemplos de atividades/aplicações I/O Bound, e suas velocidades de execução são afetadas por :
- Transferência de dados pela rede
- Copiar/Mover arquivo em disco
- Consultar um banco de dados remoto
- Consultar uma API HTTP
CPU e I/O Bound
Aplicações que fazem uso intenso de CPU e dispositivos de I/O. São exemplos:
- Compressão de arquivos
- Desfragmentação de disco
Processos e Threads
Múltiplos processos
Múltiplos processos, ou processos independentes, é uma maneira simples e sem vínculo de se implementar a concorrência. O processo criador não possui nenhuma relação com o processo criado e gera a criação de um novo Processos Control Block (PCB), possuindo contextos de software e hardware completamente diferentes, assim como espaços de endereçamento de memória. Por esse motivo, o compartilhamento de estado de objetos de uma aplicação, e comunicações em geral entre processos, são operações muito custosas e devem ser evitadas.
Subprocessos
Em python, chamados simplesmente de múltiplos processos. Subprocessos são processos criados com vínculo hierárquico, ou seja: O processo criador é chamado de pai e, novos processos, de filho. Subprocessos não são independentes, e sua existência é condicional a existência do processo pai. A finalização do processo pai -por qualquer motivo-, automaticamente finaliza o processo filho. Subprocessos também podem ter outros Subprocessos.
A criação de processos e subprocessos é sempre um custo para o sistema operacional como um todo. É preciso alocar contexto de hardware, contexto de software e espaço em memória para cada um.
Em python, utiliza-se o módulo built-in multiprocessing para criar novos processos e aproveitar todo os núcleos disponíveis.
Normalmente, faz-se uso de múltiplos processos sempre que for possível dividir o trabalho de uso intenso de CPU (CPU Bound), a ser executado de forma cooperativa sem que seja necessária comunicação entre as partes (ou seja, sem compartilhamento de estado). Operações no modelo MapReduce são um bom exemplo de uso.
Threads
Threads foram criadas com o intuito de reduzir a criação, troca de contexto de processos (que como já falamos anteriormente, é algo custoso) e para economizar outros recursos do sistema. Threads estão sempre associadas a um único processo, que por sua vez, pode possuir múltiplas threads. Threads compartilham o processador da mesma maneira que um processo, ou seja: cada thread tem o seu próprio contexto de hardware, mas threads de um mesmo processo compartilham entre si o mesmo contexto de software e memória. Resumindo: Basicamente, forçando um pouco a barra, threads são como se fossem “processos leves” que compartilham memória entre si.
Como threads de um mesmo processo compartilham o mesmo gerenciamento de memória, não existe proteção por parte do SO a acesso de memória, sendo possível que mais de uma thread acesse e manipule o mesmo endereço de memória ao mesmo tempo. O uso desorganizado obviamente causaria inconsitências, e mecanismos de controle devem ser implementados para threads colaborem ordenadamente. Essa ordem é comumente aplicada através de exclusão mútua, que também ganha o nome de mutex (mutual exclusion semaphores), semáforos binários ou, o mais popular, Lock. O que nos leva ao famigerado, mistificado, mas pouco entendido Global Interpreter Lock (GIL).
GIL, nada mais é do que um Lock em nível de interpretador. Ou seja, o GIL existe para proteger a memória do INTERPRETADOR (aquele que lê o texto do seu código, parseia as instruções e estruturas lógicas e transforma em bytecode), e faz com que todas as threads tenham que adquirir esta lock por baixo dos panos, pra garantir a integridade das estruturas básicas. Isso parece causar um grande overhead e uma grande sensação de que, na verdade, você acaba não tendo multiplas threads de fato, tendo por consequência possivelmente com um código mais lento do que single thread, o que não é verdade. Threads são sempre mais lentas e ruins por culpa do GIL? NÃO! Especificamente em python, se esse é o caso, você está utilizando threads pra coisa errada. Existem várias situações onde threads podem ser empregadas para ganho de performance em aplicações I/O Bound. Inclusive, a documentação é muito clara sobre isso. Infelizmente, muitas pessoas que tive contato ao longo do meu tempo de programador Python, insistem em criticar laranjas por não terem gosto de banana.
CPython implementation detail: In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once (even though certain performance-oriented libraries might overcome this limitation). If you want your application to make better use of the computational resources of multi-core machines, you are advised to use
multiprocessingorconcurrent.futures.ProcessPoolExecutor. However, threading is still an appropriate model if you want to run multiple I/O-bound tasks simultaneously.
Threads em python são pthreads (posix thread) reais, e podemos criá-las utilizando uma interface de baixo nível _thread e, em mais alto nível, threading.
No próximo post vou abordar a teoria envolvida no funcionamento do Asynchronous I/O (asyncio), onde ele se encaixa nesses cenários, e dar alguns exemplos práticos de código com comparativos.
Meu objetivo é que ao final você saiba conscientemente escolher a bicicleta certa para cada tipo de ambiente.


Excelente artigo. Agradeço por compartilhar seu conhecimento com todos.
CurtirCurtir
Ótima explicação! Achei muito esclarecedor, estou começando a aprender sobre paralelismo e concorrência com Python para utilizar em um projeto e confesso que estava um pouco perdido (threading, multiprocessing ou concurrent.futures, qual seria o mais adequado?), seu post me deu uma luz. Meu projeto se encaixa na classificação I/O Bound, usei threading porque foi o primeiro que encontrei, mas parece que estou indo pelo caminho certo.
CurtirCurtir
Fantástico este post. Esclareceu muito. Muito obrigado.
CurtirCurtir
Post incrível. Claro e direto. Parabéns e obrigado.
CurtirCurtir